Land Cover Monitoring

Wageningen University
Department of Environmental Sciences
Laboratory of Geo-information Science and Remote Sensing
Contact person
Dr Jan Verbesselt
Chair group Geo-Information and Remote Sensing
Tel: + 31(0)317 485268
email: jan.verbesselt@wur.nl
Summary
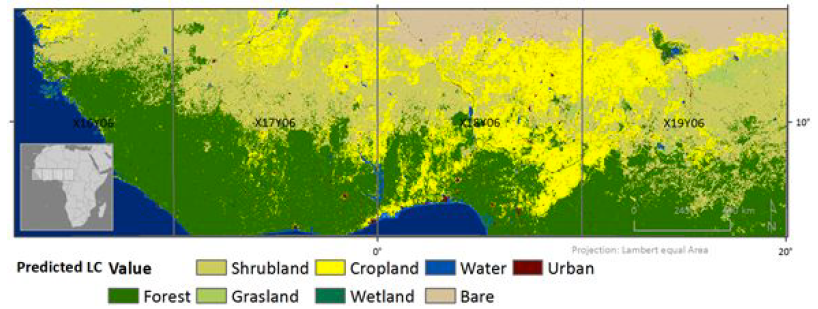
The Land Cover use case will deploy and demonstrate PROBA-V based land cover monitoring within the PV-MEP. By introducing open-source time series algorithms that take into account complex and highly variable vegetation dynamics in semi-arid ecosystems, we will develop methodologies that allow for more accurate land cover monitoring. The PROBA-V Mission Exploitation Platform (PV-MEP) will allow applying the developed methods on large amounts of PROBA-V satellite data and will allow sharing the developed open-source algorithms.
Goal
Test the PROBA-V MEP towards global scale land cover mapping and updating. Investigate the use of R&D in a VM and using open-source tools (R packages or Python Modules) published publicly.
Technical contact person
Nandika Tsendbazar, nandin.tsendbazar@wur.nl