Land Cover Monitoring and Classification
Jan Verbesselt - WUR, The Netherlands
Dainius Masiliunas - WUR, The Netherlands
Johannes Eberenz - WUR, The Netherlands
Nandika Tsendbazar - WUR, The Netherlands

Land cover (LC) mapping is one of the most common applications of remote sensing data and yet, used for a myriad of analyses and decision-making processes. As such, a variety of land cover maps have been produced based on advanced methods and data sources. However, some parts of the world, in particular areas with inter-annual variabilities in vegetation and climate, continue to be mapped with lower accuracies.
An important step to improve LC map accuracy is to take temporal variability into account. Benefitting from the dense time series data of PROBA-V, Wageningen University implemented the LC monitoring use case aimed at developing and implementing methods for time-series-based LC monitoring and fractional LC type mapping.
Time-series-based LC mapping in the Sahel region
Dense time-series-based LC monitoring is important for improved LC mapping by benefitting from variability information. Time-series metrics and vegetation phenology variables that are based on sufficient observations (3-4 years) can be used for LC classification algorithms. Our use case focused on time-series-based LC mapping in the Sahel region of Africa.
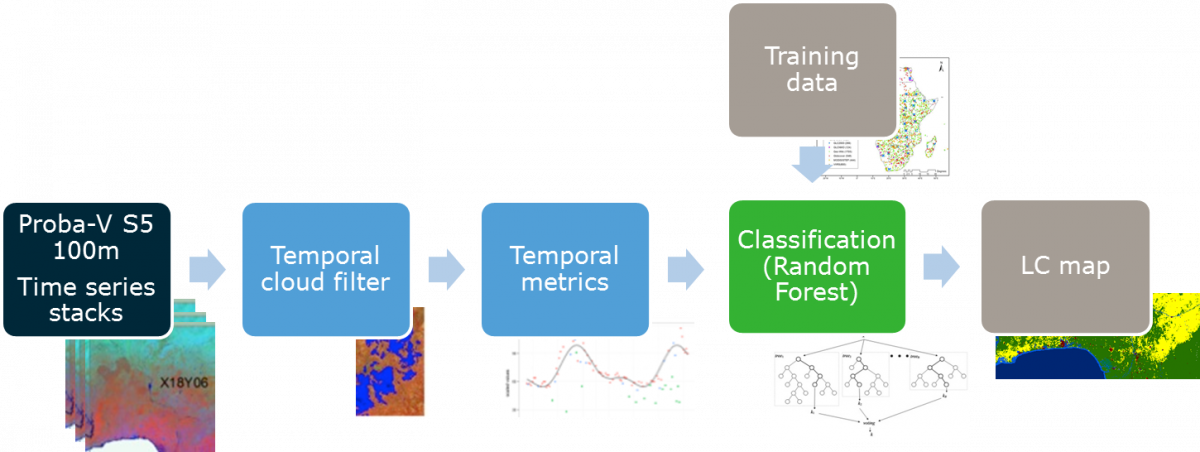
Figure 1: Land cover classification and mapping workflow
Identify the most suitable algorithm for fractional LC mapping
Fractional LC mapping is useful towards creating LC information that is flexible for different users' needs. For this, percent cover information of LC types needs to be developed and this could also exploit available time-series data of PROBA-V and other sensors. Within this use case, the algorithms for fractional LC mapping were tested in order to identify the most suitable algorithm. The test case was done in a temperate-boreal region gradient with focus on different forest types.
Land cover monitoring use case also focused on the reproducibility and user friendliness of LC mapping algorithms. For this, open source LC mapping algorithms with modular processing steps were implemented to develop and publish the LC mapping algorithms through GitHub.
Machine learning algorithms running on the PROBA-V MEP virtual machines
PROBA-V MEP was used to access the whole archive of 100m resolution top-of-canopy PROBA-V imagery over the areas of interest, as well as to process this imagery into land cover classification maps. R (RStudio Server, BFAST, machine learning algorithms, parallel packages) and Python (Anaconda, machine learning algorithms) were used by connecting to the PROBA-V MEP virtual machines remotely. The cores available through the PROBA-V MEP virtual machine were used in parallel in order to lower the processing time needed for the amount of input data.
The GeoTIFF files at the areas of interest were accessed and preprocessed in order to remove areas covered by clouds. Additional cloud filtering was applied by using temporal cloud filtering. Then vegetation indices were derived from the data. This data, as well as other openly-accessible data such as digital elevation models, was used to build a number of machine learning models in order to make predictions of LC types at areas of interest.

Figure 2: Forest cover (FC) results comparison. These results show that the PROBA-V 100 m data has great potential for LC and FC mapping over semi-arid Africa. With the Proba-V 100m data, FC mapping was similar to Landsat based TREES3 product and provides higher accuracies than global LC maps.
Easy access to the whole archive of PROBA-V 100 m resolution top-of-canopy
The MEP is useful for the ability to easily access data as if it was locally stored and process it with a large number of cores and a good amount of RAM available. The unmanaged nature of the virtual machines also allows for more freedom in choosing the software for processing the data, as well as writing scripts that are for the most part reproducible on any other Linux virtual machine, which is important in the scientific field.
During iteration 3 the PROBA-V MEP team will address the interaction with an R graphical interface. The installed RStudio works fine but using it over X2go is rather slow and it also tends to not be very stable. For the RStudio Server, a solution for integration in the remote authentication mechanism is needed to prevent permission confusion between the local user for RStudio Server and the remote user you log in as through SSH and X2go.
PROBA-V MEP supports SparkR and a future improvement by using SparkR could solve the RStudio Server problem, while also speeding up the processing of the data.
Future evolutions
The MEP is useful for processing more than just PROBA-V data. The Sentinel 1 and 2, and Landsat 7 and 8 Collections are useful to have available, since that data can be combined with PROBA-V data for improving time series and spatial resolution. MODIS data could also be used as a source of history prior to the launch of PROBA-V. With the Terrasope platform (https://www.terrascope.be/) VITO addresses the need for Sentinel data together with the PROBA-V and SPOT VEGETATION data.
The results of the research could be offered as a product, but that would involve a process of extending the area of interest to a continental or global scale and automating it, which in turn is a time-consuming process both in terms of the size of the data to be processed and the time it takes to set up such an infrastructure. It could be done if there is enough interest, available resources and infrastructure available.
References
- MSc thesis "Fuzzy land cover classification method assessment using PROBA-V satellite data" by Dainius Masiliunas, Wageningen University & Research (not published yet)
- Eberenz, J. et al. Evaluating the Potential of PROBA-V Satellite Image Time Series for Improving LC Classification in Semi-Arid African Landscapes. Remote Sensing 8, 987 (2016).